Algorithme des k plus proches voisins (knn)
Introduction
L’algorithme des k plus proches voisins appartient à la famille des algorithmes d’apprentissage automatique (machine learning).
Le terme machine learning a été utilisé pour la première fois par l’informaticien américain Arthur Samuel en 1959. Ces algorithmes ont connu un fort regain d’intérêt au début des années 2000, notamment grâce à la quantité importante de données disponibles sur Internet.
L’algorithme des k plus proches voisins est un algorithme d’apprentissage supervisé : il nécessite des données labellisées.
À partir d’un ensemble \( E \) de données labellisées, il est possible de classer une nouvelle donnée ne possédant pas de label.
Cet algorithme constitue une bonne introduction aux principes du machine learning car il est relativement simple et très visuel.
Principe de l’algorithme
L’algorithme des k plus proches voisins ne nécessite pas de phase d’apprentissage explicite. Il suffit de stocker les données.
Soit un ensemble E contenant n données labellisée :
-
Soit une donnée u qui n’appartient pas à E et qui ne possède pas de label.
-
Soit d une fonction qui renvoie la distance entre la donnée u et une donnée quelconque appartenant à E.
-
Soit un entier k inférieur ou égal à n.
Voici le principe de l’algorithme de k plus proches voisins :
- On calcule les distances entre la donnée u et chaque donnée appartenant à E à l’aide de la fonction d
- On retient les k données du jeu de données E les plus proches de u
- On attribue à u la classe qui est la plus fréquente parmi les k données les plus proches.
Différentes distances peuvent être utilisées : - Distance euclidienne - Distance de Manhattan - etc...
Activité n°1
Dans un repère cartésien, Quelle formule permet de déterminer la distance d entre deux points A et B définis par leurs coordonnées respectives (Xa,Ya) et (Xb,Yb).
Une piste
Peut-être avez vous entendu parler de la distance Eclidienne
distance Euclidienne : \(d=\sqrt{(Xa-Xb)^2 + (Ya-Yb)^2}\).
Une autre piste
Et peut être même de la distance Manhattan
distance Manhattan : \(d=|Xa-Xb|+|Ya-Yb|\)
Calcul de la distance Euclidenne
Calculer la distance Euclidienne entre le point A(1,1) et le point B(3,2)
la réponse
\(d=\sqrt{5}\)
Calcul de la distance Manhattan
Calculer la distance Manhattan entre le point A(1,1) et le point B(3,2)
la réponse
\(d=3\)
Étude d’un exemple
Les données
Nous avons choisi ici de nous baser sur le jeu de données ”iris de Fisher” pour chaque entrée nous avons :
- Longueur des sépales (cm)
- Largeur des sépales (cm)
- Longueur des pétales (cm)
- Largeur des pétales (cm)
- Espèce (label) :
- Iris setosa
- Iris virginica
- Iris versicolor
Il est possible de télécharger ces données au format csv avec le fichier iris2.csv
Bibliothèques Python utilisées
Nous allons utiliser 3 bibliothèques Python :
pandas→ gestion des données issues du fichier csvmatplotlib→ visualisation des données (tracer des graphiques)scikit-learn→ implémentation de k-NN
Une première visualisation des données
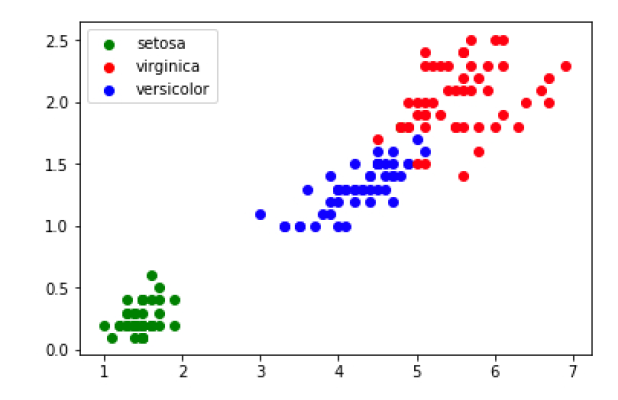
Une fois le fichier csv téléchargé, il est possible d’écrire un programme permettant de visualiser les données sous forme de graphique (abscisse : ”petal_length”, ordonnée : ”petal_width”) :
L'exécution du programme de visualisation doit vous donner la figure suivante :
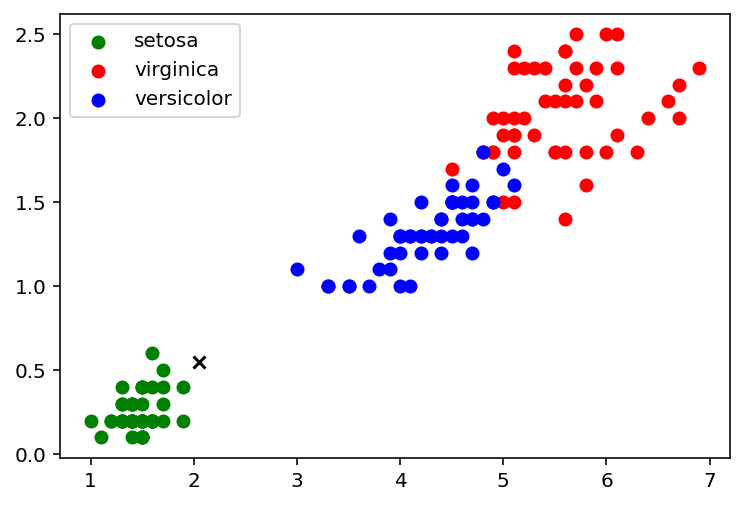
Question
Dans l’exemple ci-dessus (figure 2) A quelle espèce appartient l’iris qui a été ajouté au jeu de données ?
Réponse
Sans aucun doute dans cet exemple l'élément u appartient à l'espèce "setosa"
Examinons un autre cas (exemple : largeur pétale = 0,75 cm ; longueur pétale = 2,45 cm)
Implémentons cet élément u dans notre programme de visualisation
Insérez les lignes ci-dessous à la ligne 13 du programme de visualisation
A l'execution du programme, vous devez obtenir la figure 3 ci-dessous
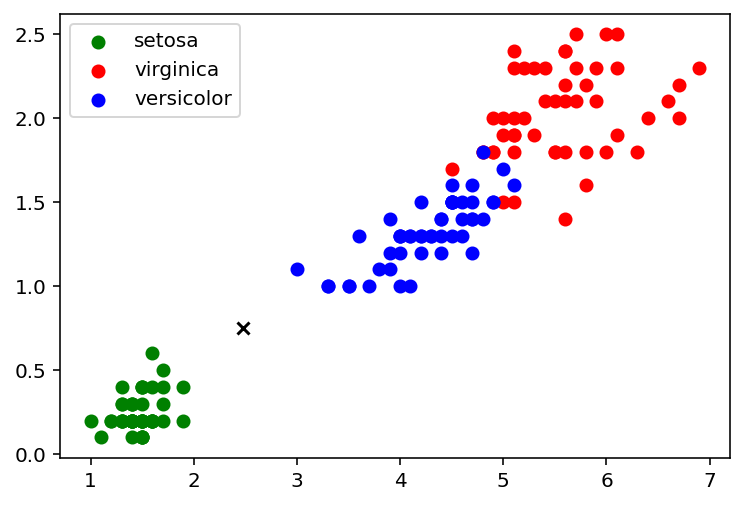
activité
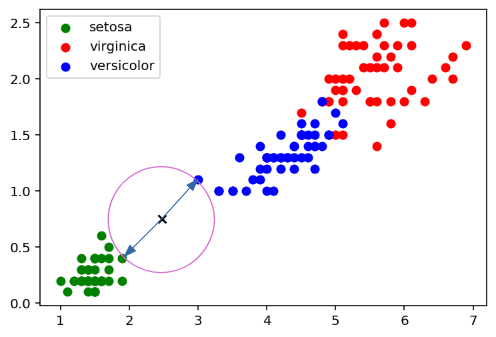
Proposer une solution graphique permettant de déterminer la variété d'iris à laquelle appartient l'élément u.
réponse
L'utilisation d'un compas centré sur le point u dessine le cercle passant par le point le plus proche permet de définir la variété de cet iris.
Quels sont les avantages et inconvénients que présentent cette solution ?
réponse
Méthode rapide, mais peu précise car elle dépend de nombreux paramètres de tracés et de mesures.
Dans le cas ci-dessus, la méthode graphique est trop imprécise et ne suffit donc plus.
Utilisation d'une méthode plus scientifique
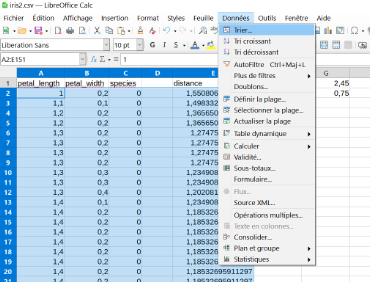
Ouvrir avec libreoffice Calc le fichier précédement téléchargé et l'enregistrer au format "Classeur Excel" (.xlsx). Nous allons calculer la distance qui sépare le point "u" de chacun des autres points.

On applique la formule (copiée) aux autres lignes de données.
Il faut sélectionner toutes les données à partir de la ligne 2
Interprétation des résultats
Pour la première ligne, La colonne species nous indique la valeur 2. Au delà de la 1ère ligne on remarque que la valeur 0 est nettement plus présente dans la colonne species. Donc si l'on décide de déterminer à quelle espèce appartient notre inconnu en cherchant l'individu le plus proche, le calcul nous oriente vers l'espèce versicolor Mais si l'on prend les 3 individus et plus parmis les plus proches c'est l'espèce setosa qui est la plus représentée.
Cette méthode efficace et répétitive se prête aisément au calcul informatique
Détermination de l'espèce à l'aide de Python
La bibliothèque Python scikit-learn propose un grand nombre d’algorithmes lié à l’apprentissage automatique (c’est sans aucun doute la bibliothèque la plus utilisée en apprentissage automatique). Parmi tous ces algorithmes, scikit-learn propose l’algorithme des k plus proches voisins. Voici un programme Python permettant de résoudre le problème évoqué ci-dessus (largeur pétale = 0,75cm ; longueur pétale = 2,45 cm) :
Dans un 1er temps, vous allez télécharger le fichier iris.csv complet
L'exécution du programme confirme, heureusement, qu'en comparant l'iris inconnu u autres autres iris ayant des carctéristiques proches que la probabilité qu'il soit de l'espèce setosa est très élevée. Il est interessant maintenant d'utiliser le programme pour d'autres valeurs de :
-la longueurs des pétales
-la largeur des pétales
-la valeur de k (nombre de voisins les plus proches)